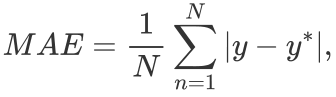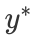|
|
| FCS | 前沿研究:基于深度标记分布学习的年龄估计 |
|
论文标题:Practical age estimation using deep label distribution learning
期刊:Frontiers of Computer Science
作者:Huiying ZHANG, Yu ZHANG, Xin GENG
发表时间:15 Jun 2021
DOI:10.1007/s11704-020-8272-4
微信链接:点击此处阅读微信文章
原文信息
• 标题:
Practical age estimation using deep label distribution learning
• 原文链接:
https://journal.hep.com.cn/fcs/EN/10.1007/s11704-020-8272-4
• 引用格式:
Huiying ZHANG, Yu ZHANG, Xin GENG. Practical age estimation using deep label distribution learning. Front. Comput. Sci., 2021, 15(3): 153318
• 公众号推文链接:
提升面部年龄识别的实用方法
1.导读
年龄估计是当下深度学习研究的一个热门领域,其目标是通过一个人的一些外部特征,去准确的估计其年龄。年龄估计拥有广阔的应用场景,如视频监控、产品推荐、人机交互、市场分析、用户画像、年龄变化预测。在现阶段,年龄估计问题的准确性很大程度上取决于是否有一个有足够多标记数据的训练集,但由于收集从童年到成年乃至晚年的照片并打上年龄标签是困难的,现有的面部数据集只有足够的面部图像,以至年龄估计缺乏大量的训练集,使得年龄估计算法效率低下。
当下,深度标记分布学习(Deep Label Distribution Learning)采用卷积神经网络(CNN)和标记分布学习从真实年龄和相邻年龄进行一个模糊性学习,已被证明优于目前最先进的框架。然而,DLDL假设了一个粗糙的标签分布,它涵盖了任何给定的年龄标签的所有年龄。如果能够提出一个覆盖合理年龄数量的标记分布,这样相邻标记和真实标记的相关性会更强,以至于能更好的发挥这种模糊性学习的优势。
基于以上考虑,本文提出了一种更实用的标签分布范式:限制年龄标签分布,只覆盖合理数量的相邻年龄。此外,文章还探索了不同的标签分布,以提高所提出的学习模型的性能。最终使用CNN和改进的标签分布学习来估计年龄。实验结果表明,与DLDL方法相比,该方法对面部年龄识别更有效。
2.主要方法
首先文章对年龄估计的图像样本建模,定义x表示图像样本实例,i表示x的年龄标签数量,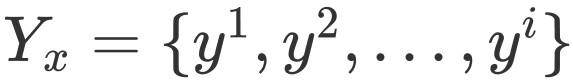 即为样本x对应的i个标签。对于每一个标签,我们定义
即为样本x对应的i个标签。对于每一个标签,我们定义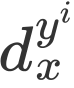 来描述样本属于该年龄标签的可能性,描述度的值越大,这种可能性也就越高。其次满足
来描述样本属于该年龄标签的可能性,描述度的值越大,这种可能性也就越高。其次满足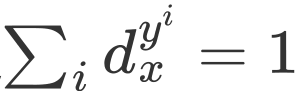 ,这保证了是一个标记分布。下图展示了三种形式的标记分布:
,这保证了是一个标记分布。下图展示了三种形式的标记分布:
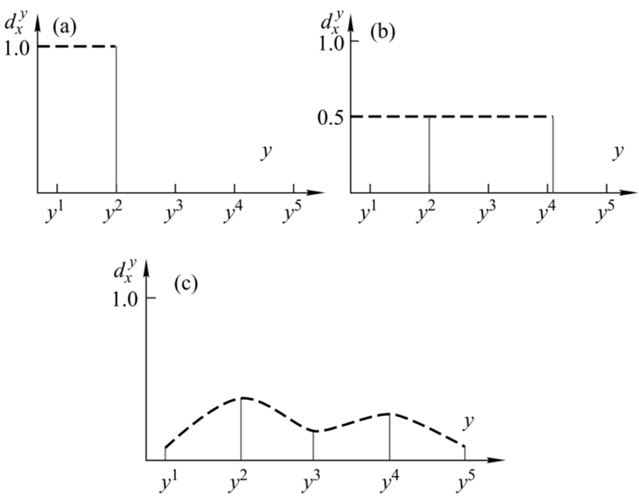
图1
图1中(a)图表示样本x只有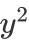 这一个标签,图(b)表示样本x有和
这一个标签,图(b)表示样本x有和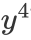 两个标签,且两种标签的描述度
两个标签,且两种标签的描述度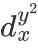 和
和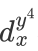 相等都为0.5,图(c)则是标记分布的一般情况,它满足
相等都为0.5,图(c)则是标记分布的一般情况,它满足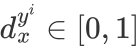 且
且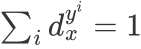 。
。
为了进一步的进行深度学习,文章定义训练集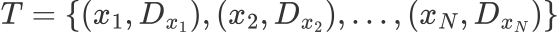 ,N为面部图像的数量。
,N为面部图像的数量。 表示第n张人脸图像的标签分布。年龄标记分布学习的目的是从训练集T 中学习一个条件概率分布函数
表示第n张人脸图像的标签分布。年龄标记分布学习的目的是从训练集T 中学习一个条件概率分布函数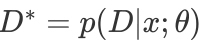 ,其中D 是一个真实分布,而
,其中D 是一个真实分布,而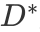 是预测分布。所以我们要解决的问题即是学习合适的参数向量
是预测分布。所以我们要解决的问题即是学习合适的参数向量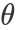 ,从而使与D 相似。而度量两个分布的相似性有很多标准,如余弦散度、詹森-香农散度、库尔贝克-莱布勒散度。为了进一步解决问题,在本文中,选择了库尔贝克-莱布勒散度(KL散度)来解决这个问题:
,从而使与D 相似。而度量两个分布的相似性有很多标准,如余弦散度、詹森-香农散度、库尔贝克-莱布勒散度。为了进一步解决问题,在本文中,选择了库尔贝克-莱布勒散度(KL散度)来解决这个问题:
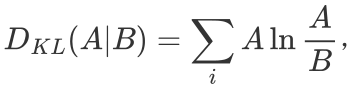
(1)
根据最优KL散度,确定了最优参数向量:
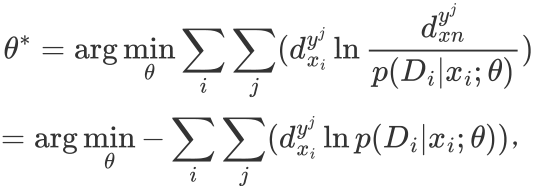
(2)
进而当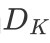 为地面真值分布时,
为地面真值分布时,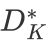 为预测标签分布。简化等式的公式(1),最佳的
为预测标签分布。简化等式的公式(1),最佳的 是由下式得到:
是由下式得到:
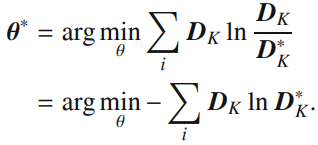
(3)
为了得到优化后的,可以推断出是由最小化和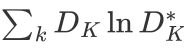 决定的。文章中则将损失函数定义为
决定的。文章中则将损失函数定义为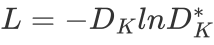 。那么对于该损失就可用梯度下降函数来最小化目标函数,而梯度可以由导数求得为:
。那么对于该损失就可用梯度下降函数来最小化目标函数,而梯度可以由导数求得为:
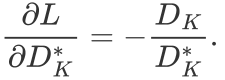
(4)
梯度下降函数的目的是获得最优的,进而整个算法框架的伪代码如算法1所示:
算法1.整体框架

最终通过训练得到合适的\theta最终得到想要的预测模型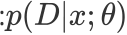 。
。
3.主要贡献
• 文章探索不同的分布来提高所提出的学习模型的性能,并最终选择了高斯分布。图2给出了实际年龄a的两个标签分布,即三角形分布和高斯分布。由于年龄,是离散点,分布是一个连续函数,文章将连续随机变量的概率分布转化为描述度。实验结果表明,采用高斯分布的结果优于三角分布。假设真年龄为a,高斯函数为:
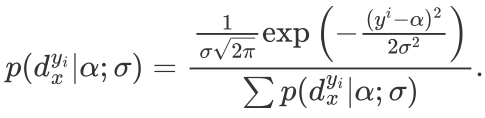
(5)
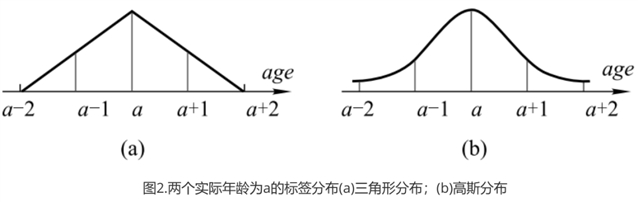
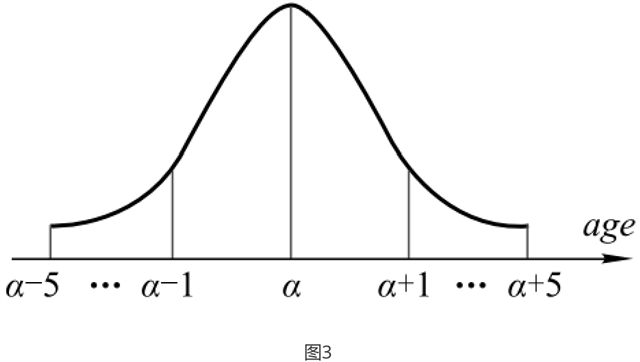
• 文章通过引入了一个只覆盖合理数量的相邻年龄的简单标签分布,改进了年龄估计的深度标签分布学习方法。为了得到更精准的预测值,本文讨论选择了更合适的标记分布的生成方法。文章认为很显然一个25岁的人是不能从65岁人的脸上获得可靠的特征信息。换句话说,当两个年龄段之间的差异很大时,就没有相关性了。如果一个人的真实年龄和预测年龄的绝对值大于5岁,这种预测结果是不可接受的。因此,本文将年龄标签的分布简化为图3。从图3中可以看出,这种简化的标签分布可以看作是高斯分布的近似值,但年龄的分布固定在[−5,+5]范围内,假设年龄超过这个范围的概率为零。为了选择合理的年龄分布,本文选择了不同的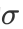 ,如0、0.5、1.0、1.5、2.0、2.5、3.0、3.5、4.0等,并在实验部分对于不同的训练集验证选择合适的。
,如0、0.5、1.0、1.5、2.0、2.5、3.0、3.5、4.0等,并在实验部分对于不同的训练集验证选择合适的。
• 文章对现有的深度卷积网络进行了扩展和改进,采用的Inception v4的CNN能够自动有效地学习复杂的人脸特征。其次,该方法采用了简化的标签分布学习。得到的标签分布学习是基于相邻年龄的相关性。合理的标签分布学习不仅能有效地学习地面真实年龄的信息,而且还能有效地学习相邻年龄的信息,所以与其他年龄估计算法相比,它的训练速度更快,性能也更好。
4.实验
实验设置
人脸图像的预处理是特征提取的基础。图像预处理可以减少不相关信息的干扰。文章使用DPM模型来检测面部区域。该过程分为四个阶段如下图4所示:(a) 获得原始图像,(b) 确定有效面积、检查点并对齐位置,(c) 根据面部区域,可以检测到5个关键点,包括两个眼中心、鼻尖和两个嘴角,(d) 通过这五个关键点,保持脸部直立的姿势。对人脸图像进行检测、定位和裁剪。经过预处理后,可以合理的去掉坏脸图像,比如没有脸,没有下巴的图像。而为了输入cnn,所有的面部图像都被调整到一个统一的大小,由三个通道表示,尺寸为224∗224∗3。

文章使用MAE(平均绝对误差)来估计模型的性能:
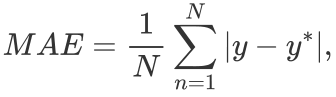
(6)
其中y表示面部图像中标记的真实年龄 , 表示估计的年龄。
, 表示估计的年龄。
文章使用了两个开放的年龄数据库MORPH和FG-NET。实验随机分割了每个数据集,其中80%用于训练,20%用于测试。drop out的概率被设置为0.8。对于MORPH,每一块数据的最小批量大小被设置为80,FG-NET被设置为2。初始学习率设置为0.001。迭代的总数被设置为80。我们选择了一组不同的标签分布,其值分别为0、0.5、1.0、1.5、2.0、2.5、3.0、3.5、4.0、5.0。\
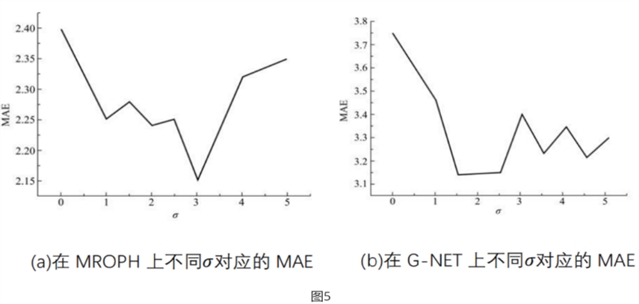
如下图5(a)和图5(b)分别显示了不同在MORPH和FG-NET上的MAE。对于MORPH,=3.0时,MAE=2.15,=3.0是一个生成适当的标签分布的很好的可选参数。对于FG-NET,=1.5时,MAE=3.14,=1.5是生成适当的标签分布的一个很好的可选参数。
实验结果
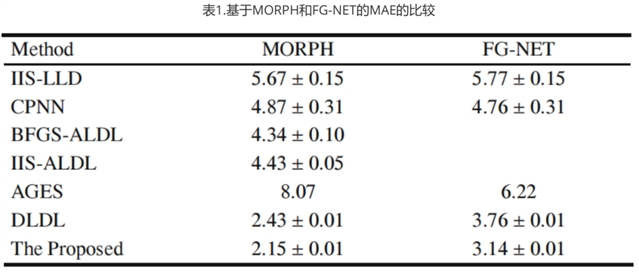
如下表1将所提方法与不同方法的性能进行了比较。该方法对MORPH和FG-NET的MAE值分别为2.15和3.14。所提出的方法的结果优于其他方法。
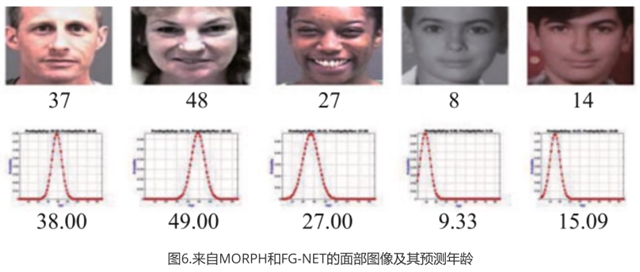
如下图6所示的一些来自MORPH和FG-NET的真实年龄的面部图像,图像下方对应于的是所提方法的预测年龄和标签分布。可以看出估计的年龄接近于真实的年龄。
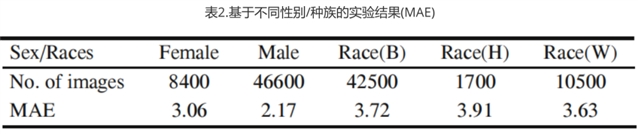
其次结果如下表2所示,文章还测试了该方法在不同性别/种族的人的实验结果。结果并不令人满意。潜在的原因可能是:(1)与面部图像的数量有限有关,(2)单数据训练的模型不如多类型数据的模型训练有效。
摘要
Age estimation plays an important role in humancomputer interaction system. The lack of large number of facial images with definite age label makes age estimation algorithms inefficient. Deep label distribution learning (DLDL) which employs convolutional neural networks (CNN) and label distribution learning to learn ambiguity from ground-truth age and adjacent ages, has been proven to outperform current state-of-the-art framework. However, DLDL assumes a rough label distribution which covers all ages for any given age label. In this paper, a more practical label distribution paradigm is proposed: we limit age label distribution that only covers a reasonable number of neighboring ages. In addition, we explore different label distributions to improve the performance of the proposed learning model. We employ CNN and the improved label distribution learning to estimate age. Experimental results show that compared to the DLDL, our method is more effective for facial age recognition.
解读:徐宁 东南大学
审核:张琨 合肥工业大学

Frontiers of Computer Science
Frontiers of Computer Science (FCS)是由教育部主管、高等教育出版社和北京航空航天大学共同主办、SpringerNature 公司海外发行的英文学术期刊。本刊于 2007 年创刊,双月刊,全球发行。主要刊登计算机科学领域具有创新性的综述论文、研究论文等。本刊主编为周志华教授,共同主编为熊璋教授。编委会及青年 AE 团队由国内外知名学者及优秀青年学者组成。本刊被 SCI、Ei、DBLP、INSPEC、SCOPUS 和中国科学引文数据库(CSCD)核心库等收录,为 CCF 推荐期刊;两次入选“中国科技期刊国际影响力提升计划”;入选“第4届中国国际化精品科技期刊”;入选“中国科技期刊卓越行动计划项目”。
《前沿》系列英文学术期刊
由教育部主管、高等教育出版社主办的《前沿》(Frontiers)系列英文学术期刊,于2006年正式创刊,以网络版和印刷版向全球发行。系列期刊包括基础科学、 、工程技术和人文社会科学四个主题,是我国覆盖学科最广泛的英文学术期刊群,其中13种被SCI收录,其他也被A&HCI、Ei、MEDLINE或相应学科国际权威检索系统收录,具有一定的国际学术影响力。系列期刊采用在线优先出版方式,保证文章以最快速度发表。
中国学术前沿期刊网
http://journal.hep.com.cn
特别声明:本文转载仅仅是出于传播信息的需要,并不意味着代表本网站观点或证实其内容的真实性;如其他媒体、网站或个人从本网站转载使用,须保留本网站注明的“来源”,并自负版权等法律责任;作者如果不希望被转载或者联系转载稿费等事宜,请与我们接洽。

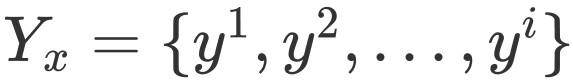
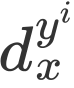
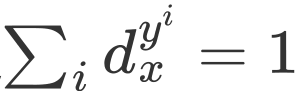

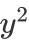 这一个标签,图(b)表示样本x有
这一个标签,图(b)表示样本x有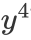 两个标签,且两种标签的描述度
两个标签,且两种标签的描述度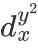 和
和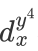 相等都为0.5,图(c)则是标记分布的一般情况,它满足
相等都为0.5,图(c)则是标记分布的一般情况,它满足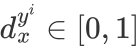 且
且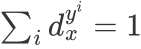
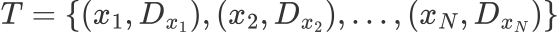 ,N为面部图像的数量。
,N为面部图像的数量。 表示第n张人脸图像的标签分布。年龄标记分布学习的目的是从训练集T 中学习一个条件概率分布函数
表示第n张人脸图像的标签分布。年龄标记分布学习的目的是从训练集T 中学习一个条件概率分布函数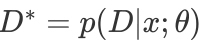 ,其中D 是一个真实分布,而
,其中D 是一个真实分布,而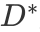 是预测分布。所以我们要解决的问题即是学习合适的参数向量
是预测分布。所以我们要解决的问题即是学习合适的参数向量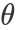 ,从而使
,从而使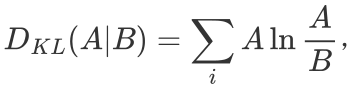
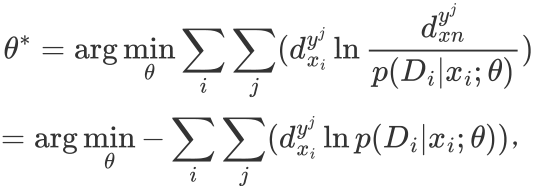
 为地面真值分布时,
为地面真值分布时,

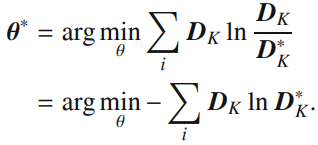
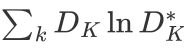
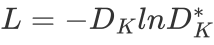
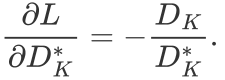

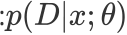
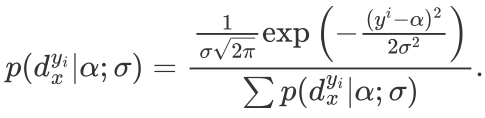

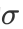 ,如0、0.5、1.0、1.5、2.0、2.5、3.0、3.5、4.0等,并在实验部分对于不同的训练集验证选择合适的
,如0、0.5、1.0、1.5、2.0、2.5、3.0、3.5、4.0等,并在实验部分对于不同的训练集验证选择合适的