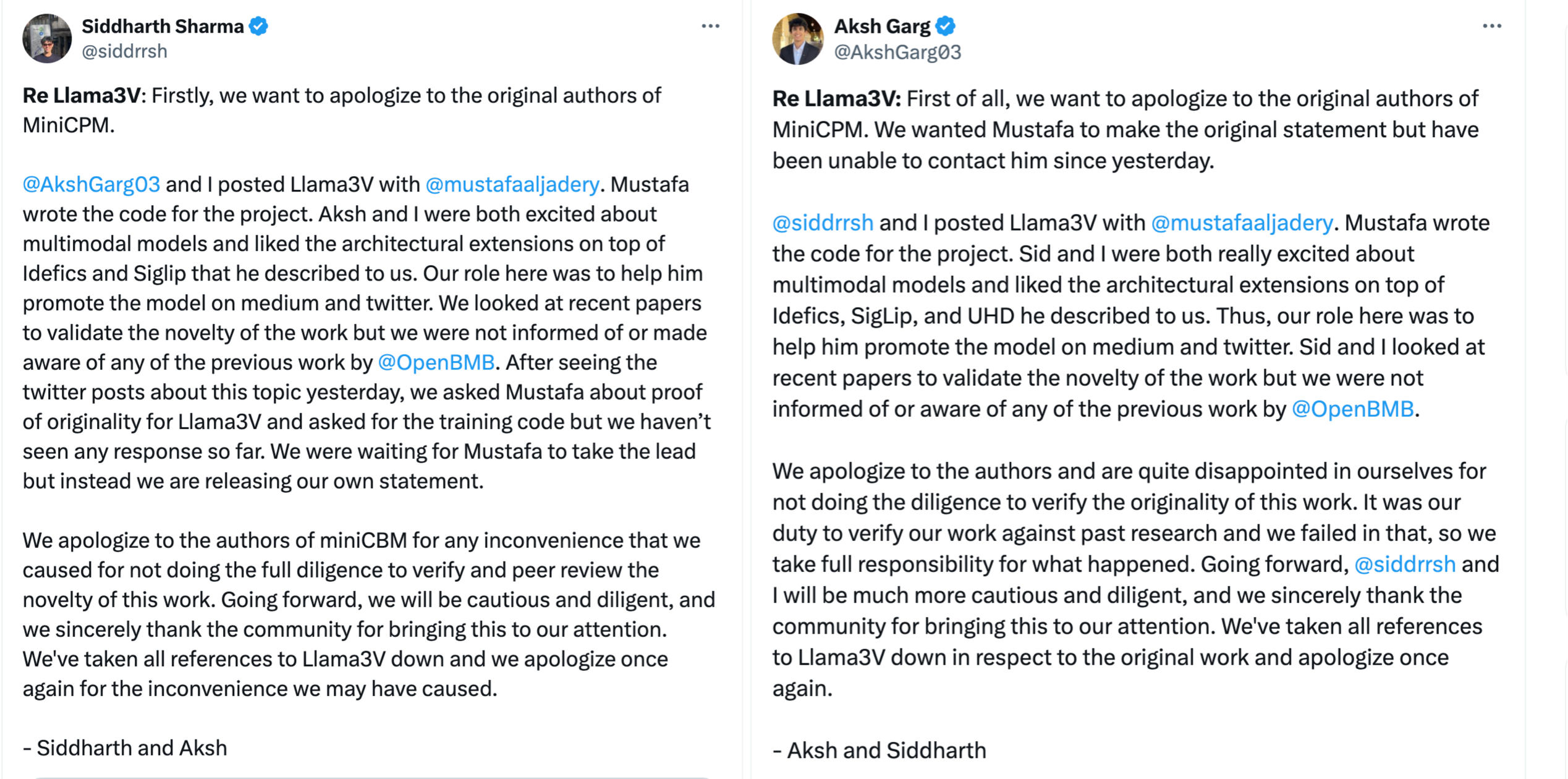
一人失联、两人致歉,连日来轰动一时的“斯坦福大学AI团队抄袭中国开源大模型”事件迎来了最新进展。
北京时间6月4日凌晨,两位来自美国斯坦福大学的本科生——席德哈斯·夏尔马( Sharma)和阿克什·加尔格(Aksh Garg)在社交平台X(原“推特”)上主动承认了抄袭行为,并“向原作者们道歉”。
Siddharth和Aksh分别在X上发推致歉。 截图自X平台
但作为三人团队中的关键人物——负责其项目代码部分的穆斯塔法·阿贾德里(Mustafa Aljadery),却“失联”了。“我们原本希望由Mustafa 首发声明,但自昨天以来一直无法联系到他。”Siddharth和Aksh在推文中写道。
美国名校——斯坦福大学的研究团队抄袭来自中国的大模型,这在许多中国网友看来堪称“魔幻”,该事件也被一些网友认为具有一定的标志性意义:“是时候重新认识中国AI的水平了。”
“斯坦福抄袭事件”始末
一切始于5月29日,一款名为“Llama3-V”的多模态大模型在开源社区GitHub上火起来。
来自斯坦福的创始团队声称,仅用500美元成本,就能基于Llama3训练出一个SOTA开源多模态模型。尽管规模不大(80亿参数),但它能在性能上比肩“顶流”的GPT-4v、Gemini Ultra等。
惹眼的宣传和斯坦福大学名校背景,很快就将Llama3-V推至聚光灯下。不出两日,Llama3-V就在HuggingFace的社区榜单(HuggingFace Trending)中跻身前五。
只有真金不怕火炼。国内AI领域的学者“Magic Yang”越看越不对劲,他发现Llama3-V的架构和代码,与一款来自中国团队的大模型几乎一模一样,即清华大学和面壁智能团队基于开源模型Llama3联合开发的MiniCPM-Llama3-V 2.5,该模型于5月中旬发布。
但是,Magic Yang没有看到斯坦福大学团队对中国团队模型表示任何形式的“致敬或感谢”——这在开源项目中往往是必要的。
他随即在GitHub下留言提出质疑,但换来的却是斯坦福大学团队的诡辩或回避,后者甚至声称自己的工作早于中国团队。而当他用模型代码对比、分词器对比等提出实质性质疑,后者竟然直接删除了他的留言。
这彻底激怒了Magic Yang。他转而来到清华大学和面壁智能开发的模型GitHub项目下爆料,并提醒面壁智能团队注意此事。
收到提醒后,面壁智能团队很快展开了调查。在Magic Yang提供证据的基础上,他们得出了同样的结论:“比较确信Llama3-V是对我们MiniCPM-Llama3-V 2.5的套壳”。
面壁智能首席科学家、清华大学长聘副教授刘知远给出“套壳”判断的一大理由,是其对于清华简的识别能力。
两模型对清华简的识别几无二致。刘知远 供图 ?
“比较有意思的证据是,MiniCPM-Llama3-V 2.5研发时内置了一个‘彩蛋’,就是对‘清华简’的识别能力。这是我们从清华简逐字扫描并标注的数据集,并未公开,而Llama3-V展现出了一模一样的清华简识别能力,连做错的样例都一样。”刘知远说。
面壁智能CEO李大海介绍,这项工作是团队耗时数月、从卷帙浩繁的清华简中一个字一个字扫描下来,并逐一进行数据标注、融合进模型中的。
刘知远(右)与李大海(左)在分享活动中。 图源:面壁智能 ?
斯坦福教授愤怒,中国作者:选择原谅
面对Siddharth和Aksh几乎一模一样的致歉推文以及疑似“甩锅”队友(那位失联的“代码哥”)的操作,斯坦福人工智能实验室主任克里斯托弗·曼宁(Christopher Manning)在得知该事件后,忍不住发推批评:“这是典型的不承认自己错误!”(How not to own your mistakes!)
Christopher Manning同时表示,他对这一研究毫不知情:“这似乎是由几位本科生完成的,其中一些人在斯坦福大学。”不过,他认为抄袭事件是在给斯坦福大学蒙羞:“‘成功之前先假装成功’,这在硅谷是不光彩的。”
在被爆料之后、发道歉推文之前,Llama3-V团队“出于对原创者的尊重”,已经在Huggingface、GitHub上删除和撤回了该模型。
“开源共享的基石是对开源协议的遵守,对其他贡献者的信任,对前人成果的尊重和致敬,Llama3-V团队无疑严重破坏了这一点。”刘知远感慨,人工智能的飞速发展离不开全球算法、数据与模型的开源共享,面壁智能团队此次开源的MiniCPM-Llama3-V 2.5就用到了最新的Llama3作为语言模型基座。
不过,他表示,Llama3-V团队在受到质疑后已在Huggingface删库,而且团队三人中的两位也只是斯坦福大学本科生,他们“未来还有很长的路,如果知错能改,善莫大焉”。
李大海则在他的社交媒体动态中谈到,尽管对斯坦福大学学生团队套壳事件深表遗憾,但同时也认为“这也是一种受到国际团队认可的方式”。
中国AI崛起了吗?
值得一提的是,在“套壳事件”发生之前,MiniCPM模型并未受到太多的关注。这一点,就连谷歌DeepMind研究员、深度学习模型ViT的作者之一卢卡斯·拜耳(Lucas Beyer)都为之鸣不平。
“这起事件中有趣的一部分是,斯坦福学生所描绘的‘低成本、高性能’模型是存在的,它就是MiniCPM-Llama3-V 2.5。”卢卡斯说道:“只不过它受到的关注不多,主要原因似乎是因为,它是出自中国团队——而非常春藤盟校的团队之手。”
这次事件,也让刘知远感慨良多。“过去十几年科研经历的斗转星移”让他感受到,十多年来中国AI科学技术水平其实是一直在进步的。
“回想2006年我读博时,大家的主要目标还是在国际顶级会议上发篇论文;到2014年我做老师时,只有获得国际著名会议的最佳论文等重要成果,才有机会登上系里的新闻主页。”他写道。
不过,刘知远也体会到,2022年底OpenAI推出ChatGPT之后,国内公众还是认识到了中美在AI领域的差距:“特别是2023年Llama等国际开源模型发布后,开始有‘国外一开源、国内就自研’说法。”
而今,中国团队的大模型成果被来自斯坦福大学的团队“套壳”——虽然是几个学生,但也侧面反映了中国的AI创新成果正在受到国际关注。
“从横向来看,我们显然仍与国际顶尖工作如Sora和GPT-4o有显著差距;但从纵向来看,我们已经从十几年的nobody,快速成长为人工智能科技创新的关键推动者。”刘知远说,所以,“面向即将到来的AGI时代,我们应该更加自信积极地投身其中。”
多读一点:同为开源,为何面壁智能是创新?
许多人不解:清华大学—面壁智能团队的模型也是基于Llama 3开源模型开发的,为什么他们的工作可称作创新,而斯坦福大学本科生的“工作”是套壳、抄袭呢?
其实,这两者是有性质上的不同的。
具体而言,MiniCPM-Llama3-V 2.5是在原来MiniCPM-v2和Llama3开源项目的基础上,使用公开或自有的图文等数据集进行训练、调优等升级而成的视觉语言模型,它具有视觉识别、自然语言交互等能力,具有潜在的应用前景,MiniGPT-4、LLaVA等均属于此类。
而llama3-v根本没有自己任何的创新,属于“复制—粘贴”代码和模型结构的“产品”。有行业人士指出,Llama3-V的团队是在MiniCPM-Llama3-V2.5的基础上加入高斯噪声,进而伪造出了一个不同哈希值的“新模型”。表面上看起来它变得不一样了,但实质上是完全的“套壳”。可以说,llama3-V只是MiniCPM-Llama3-V2.5的“加噪版本”。
开源社区的精神是分享,以让更多人在开源技术的基础上添砖加瓦、贡献智慧、实现价值。事实上,斯坦福大学也有许多科学家对开源社区有非常大的贡献。比如斯坦福大学计算机科学专业的华人博士生张吕敏,就对AI绘画工具的开源共享作出许多贡献。但是,将别人的开源贡献套一层外壳,再宣称是自己的成果,不仅有违开源精神,更是欺世盗名、不为人齿。
相关参考信息:
https://github.com/OpenBMB/MiniCPM-V/issues/196
版权声明:凡本网注明“来源:中国科学报、科学网、科学新闻杂志”的所有作品,网站转载,请在正文上方注明来源和作者,且不得对内容作实质性改动;微信公众号、头条号等新媒体平台,转载请联系授权。邮箱:shouquan@stimes.cn。