8月9日,一篇关于复杂数学方程新解的论文发表在了物理学领域期刊Physica Scripta上。乍一看,文章内容似乎没什么问题。然而,法国图卢兹大学的计算机科学家兼科学侦探Guillaume Cabanac在阅览这篇论文手稿的第3页时,注意到了一个不寻常的词组“重新生成响应(Regenerate response)”。
熟悉ChatGPT的人,对这个词组应该不会陌生。当你对AI的回答不满意时,按下这个功能按钮标签,就能让它重新生成新的回答。
Cabanac迅速将上述手稿中露出马脚的页面截图发布在了PubPeer上。而此前他已曝光了十几篇出现类似情况的论文。
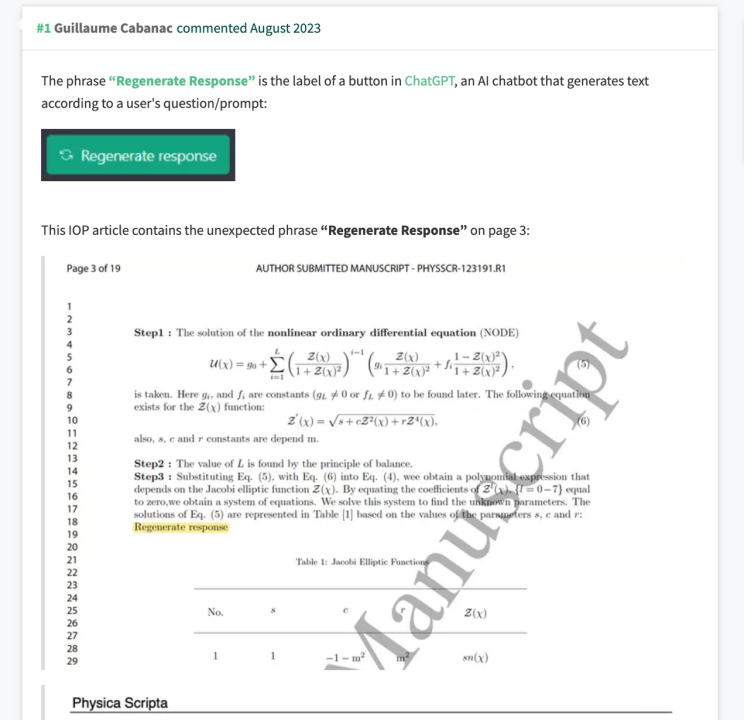
Physica Scripta论文手稿截图发布在了PubPeer上,Cabanac使用黄颜色突出显示了词组“重新生成响应”。
发现的不过是“冰山一角”
Physica Scripta的出版商是位于英国布里斯托尔的英国物理学会出版社。该机构的同行评审与研究诚信负责人Kim Eggleton表示,文章的作者后来向期刊证实,他们使用了ChatGPT来辅助起草他们的手稿。
前述论文于5月提交,于7月再次提交了修改版。在两个月的同行评审和排版过程中,竟然未发现任何异常情况。英国物理学会出版社现已决定撤回该论文,因为作者在提交时未澄清他们使用了该工具。
“这违反了我们的道德政策。”Eggleton说。
类似的案例并不鲜见。自4月以来,Cabanac已经标记了十几篇论文,并将它们发布在了PubPeer上。这些文章中都出现了一些指向ChatGPT使用迹象的词组,如“重新生成响应”或是“作为一个人工智能语言模型,我……”。

一篇Cabanac已标记并发布在PubPeer的论文截图,使用黄颜色突出显示了词组“作为一个人工智能语言模型,我……”。
在一篇发表在Elsevier旗下刊物Resources Policy上的论文中,Cabanac检测到了其他典型的ChatGPT词组。这篇论文的作者分别来自位于沈阳的辽宁大学和位于北京的商务部国际贸易经济合作研究院。
起初他只是觉得论文中的一些方程似乎没有意义。但当他浏览到论文的第3张图表时,图表上方的一段文字暴露了真相:“请注意,作为人工智能语言模型,我无法生成特定的表格或进行测试……”。
Elsevier的一位发言人对此表示,他们“意识到了这个问题”并正在调查它。
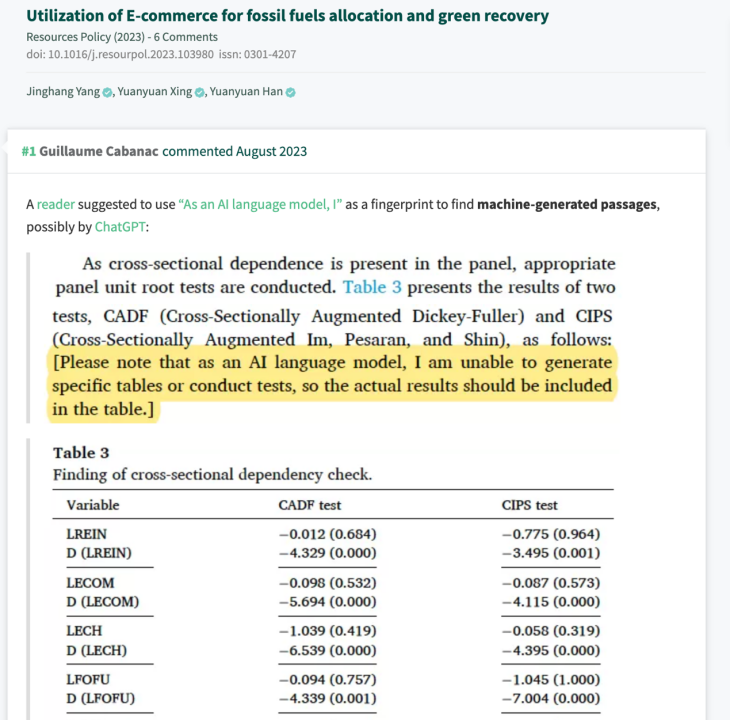
期刊Resources Policy的论文内容截图,Cabanac使用黄颜色突出显示了词组“请注意,作为人工智能语言模型,我无法生成特定的表格或进行测试……”。
事实上,包括Elsevier和Springer Nature在内的许多出版商都曾表示,允许作者使用ChatGPT和其他大型语言模型(LLM)工具以辅助他们制作稿件,但前提是必须声明在准备稿件过程中是否使用了AI或AI辅助技术。
但Cabanac发现,上述论文的作者均未对使用过ChatGPT等工作的情况予以说明。而他们之所以会被发现,是因为他们没有对文本细节进行谨慎的处理,甚至常常忘记删除哪怕最明显的人工智能生成痕迹。
考虑到这一点,那些更“聪明”更小心地处理文本,却又隐瞒自己使用了ChatGPT的论文数量,可能比已知的数量多得多。
“这些发现只不过是冰山一角。”Cabanac说。
Cabanac通过与其他科学侦探以及研究人员合作,在未经同行评审的会议论文和预印本的手稿中也发现了同样的问题。Cabanac将它们一并发布在了PubPeer上,其中部分文章的作者有时会承认他们在未声明的情况下使用了ChatGPT来帮助创作作品。
越来越难的猫鼠游戏
早在ChatGPT出现之前,科学家就已经在和计算机软件撰写的论文做斗争了。
2005年,美国麻省理工学院的3名研究人员开发了一个名为SCIgen的论文生成软件。用户可以免费下载和使用该程序,其生成的论文内容完全是虚假的。开发者的初衷是想要测试这些毫无意义的手稿是否可以通过会议的筛选程序,他们认为这些会议的存在只是为了赚钱。
2012年,法国格勒诺布尔—阿尔卑斯大学的计算机科学家Cyril Labbé在电气与电子工程师协会(IEEE)发布的会议上发现了85篇由SCIgen程序生成的假论文。两年后,Labbé又在IEEE和Springer的出版物中发现了120多篇SCIgen论文。随后,两家期刊商从它们的订阅服务中删除了这些“胡言乱语”的假论文。
针对SCIgen,Cyril Labbé专门创建了一个论文检测网站,允许任何人上传可疑的论文手稿并检查它是否是由SCIgen生成的。
SCIgen生成的文章通常包含微妙但可检测的痕迹。例如,特定的语言模式,以及因为使用自动翻译工具而误译的“异常表述”。
相比之下,如果研究人员删除了体现ChatGPT使用痕迹的标志性词组,那么更复杂的聊天机器人所生成的流畅文本“几乎不可能”被发现。
英国伦敦研究诚信办公室的研究诚信经理Matt Hodgkinson称:“这本质上是一场骗子与试图将他们拒之门外的人之间的军备竞赛”。
知名学术打假人Elisabeth Bik表示,ChatGPT和其他生成式人工智能工具的迅速崛起将为论文工厂提供火力——学术论文造假公司将会借助这些工具伪造更多的假手稿,并出售给那些希望快速提升论文产出的研究人员。
“这将使问题变得更加糟糕,”Bik说,“我非常担心学术界已经涌入了大量我们甚至不再认识的论文。”
投机者变多,守门员不够了
曾就职于新西兰北帕默斯顿梅西大学的退休心理学家,化名为Smut Clyde的研究诚信侦探David Bimler指出,隐瞒大型语言模型工具使用的期刊论文问题指向了一个更深层次的担忧:忙碌的同行评审人员通常没有时间彻底检查稿件中是否存在机器生成文本的危险信号。
“看门人的数量跟不上。”Bimler说。
Hodgkinson给出了一个或许可行的建议:ChatGPT和其他大型语言模型倾向于向使用者提供虚假的参考文献。对于希望在手稿中发现这些工具使用痕迹的同行评审人员来说,这可能是一个很好的线索。“如果引文不存在,那就是一个危险信号,”他说。
例如,撤稿观察网站报道了一篇使用ChatGPT编写的关于千足虫研究的预印本论文。丹麦自然历史博物馆的千足虫研究人员Henrik Enghoff在下载这篇论文时,注意到该文虽然引用了他的研究成果,但是他的这些成果与预印本的研究主题并不一致。
哥本哈根国家血清研究所的微生物学家Rune Stensvold则遇到了引用伪造的问题。当一个学生向他索要一份据说是他在2006年与一位同事共同撰写的论文副本时,Stensvold发现这篇文章根本就是不存在的。追溯事实发现,原来该学生曾要求人工智能聊天机器人推荐有关芽囊原虫属的论文,而聊天机器人拼凑了一篇带有Stensvold名字的参考文献。
“它看起来很真实,”Stensvold说,“这件事情告诉我,当我要审阅论文时,我可能应该首先查看参考文献部分。”
参考资料
https://www.nature.com/articles/d41586-023-02477-w
https://www.nature.com/articles/nature03653
https://www.nature.com/articles/nature.2014.14763
https://www.nature.com/articles/d41586-021-01436-7
https://retractionwatch.com/2023/07/07/publisher-blacklists-authors-after-preprint-cites-made-up-studies/
特别声明:本文转载仅仅是出于传播信息的需要,并不意味着代表本网站观点或证实其内容的真实性;如其他媒体、网站或个人从本网站转载使用,须保留本网站注明的“来源”,并自负版权等法律责任;作者如果不希望被转载或者联系转载稿费等事宜,请与我们接洽。






